GARAGE Architecture
Overview
GARAGE is a two-stage framework that couples a Graph Attention Network (GAT) with a Generative Adversarial Network (GAN) to produce high-fidelity synthetic scRNA-seq data with explicit preservation of rare cell types.
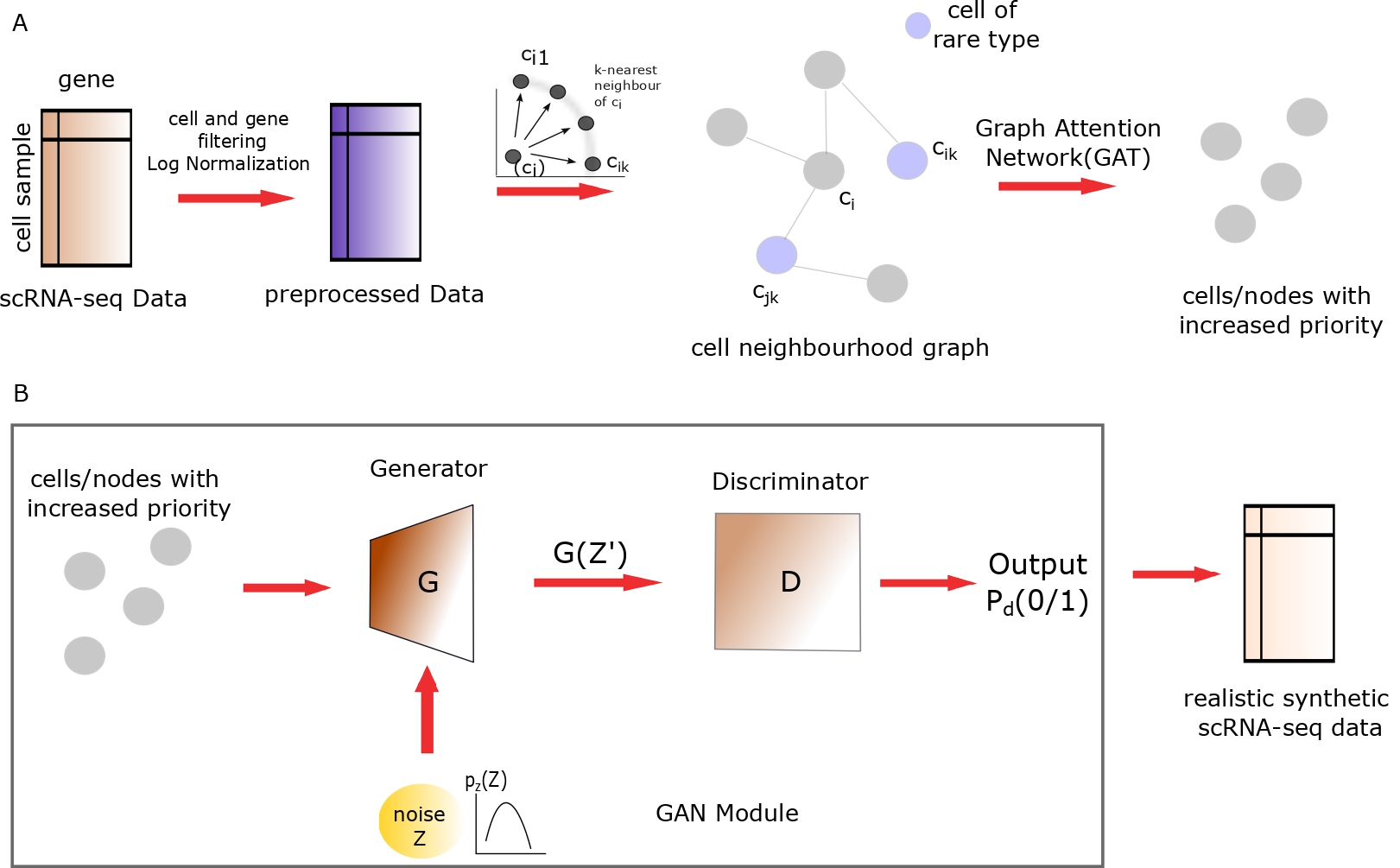
GARAGE architecture: Stage 1 (GAT cell selection) feeds priority-selected real cells into Stage 2 (GAN generation).
Stage 1: GAT-Based Cell Selection
Input
Expression matrix \(X \in \mathbb{R}^{n \times g}\) (real scRNA-seq data, \(n\) cells, \(g\) genes).
Cell-type labels \(y \in \{1, \ldots, K\}\).
Rare cell types identified by per-type count \(< \tau\) (configurable
rare_threshold).
Step-by-Step
KNN Graph Construction:
Compute a \(k\)-NN graph (\(k=5\)) from \(X\) using Ball Tree.
Each cell is a graph node; edges connect nearest neighbours in gene-expression space.
Priority Node Labelling:
Cells belonging to types with \(\text{count} < \text{rare\_threshold}\) are flagged as priority nodes.
GAT Classifier Training:
A 2-layer GAT (\(\text{heads} = 8, 1\)) learns to classify cells into their \(K\) types.
Priority nodes receive a feature boost of
priority_weight(default: 2.0) after the first GAT layer.Trained for
gat_epochs(default: 7501) iterations using cross-entropy loss.
Seed Cell Extraction:
After training, attention weights from the second GAT layer are extracted.
Per-cell attention scores are aggregated (summed over heads, then mean).
The top \(k = n \cdot \lambda\) cells are selected as seed cells, where \(\lambda\) is the
leakage_fraction.
Mathematical Formulation
For node \(i\) at layer \(l\), the GAT computes:
where \(\alpha_{ij}^{(l)}\) is the attention coefficient:
For priority nodes (rare cell types), the intermediate features are scaled:
Stage 2: GAN Generation with Attention-Guided Seeding
Input
Real expression matrix \(X\) (same as Stage 1).
Seed cell indices \(\mathcal{S}\) from Stage 1 (\(|\mathcal{S}| = k\)).
Leakage fraction \(\lambda\).
Hybrid Input Batch
The generator’s input is not pure noise. Instead, for each batch of size \(B\):
The mixed batch is then fed to the generator:
Generator Architecture
Input (g-dim) → Linear(1024) → ReLU → Linear(1024) → ReLU → Linear(g) → Sigmoid
Discriminator Architecture
Input (g-dim) → Linear(512) → ReLU → Linear(256) → ReLU → Linear(1)
Training Loop (per iteration)
Discriminator update (\(n_d\) = 5 steps):
Sample real batch: \(x_{\text{real}} \sim X\)
Generate fake batch: \(\tilde{x} = G(Z_{\text{batch}})\)
\(L_D = -\log D(x_{\text{real}}) - \log(1 - D(\tilde{x}))\)
Update \(D\) via Adam.
Generator update (\(n_g\) = 2 steps):
Sample new \(Z_{\text{batch}}\)
\(\tilde{x} = G(Z_{\text{batch}})\)
\(L_G = -\log D(\tilde{x})\)
Update \(G\) via Adam.
Repeat for
gan_total_iters(default: 20,001).
Label Smoothing
To improve training stability, GARAGE uses one-sided label smoothing:
Real labels: 0.9 (instead of 1.0) — prevents discriminator overconfidence.
Fake labels: 0.1 (instead of 0.0).
Why the Two-Stage Architecture Works
Mechanism |
Standard GAN |
GARAGE |
|---|---|---|
Noise source |
Pure random \(z \sim \mathcal{N}(0, I)\) |
Mixed: \((1 - \lambda) \cdot z \oplus \lambda \cdot x_{\text{seed}}\) |
Rare cell signal |
Lost in gradient averaging. |
Priority-weighted nodes receive extra GAT attention → selected as seeds → fed to GAN generator. |
Training stability |
Mode collapse, oscillation. |
Seed cells provide a stable biological “anchor.” |
Evaluation |
Relies on a single metric. |
Multi-metric: WD, MMD, SWD, ARI, NMI, F1, UMAP. |
Hyper-parameter Reference
All defaults are in config.py → GARAGE_DEFAULTS:
Parameter |
Default |
Description |
|---|---|---|
|
7501 |
GAT training iterations |
|
20001 |
GAN training iterations |
|
0.2 |
Fraction \(\lambda\) of seed cells in the hybrid batch |
|
5 |
Discriminator updates per iteration |
|
2 |
Generator updates per iteration |
|
0.0002 |
Generator learning rate |
|
0.0004 |
Discriminator learning rate |
|
0.9 |
Label for real data |
|
0.1 |
Label for fake data |
|
[1024, 1024] |
Hidden layer widths for \(G\) |
|
[512, 256] |
Hidden layer widths for \(D\) |
|
2.0 |
Attention boost for rare-cell types |
|
42 |
Random seed for reproducibility |
Datasets
Four built-in scRNA-seq datasets are packaged in config.py → DATASET_CONFIG:
Dataset |
Cells |
Genes |
Types |
Rare threshold |
|---|---|---|---|---|
Yan |
124 |
10,564 |
6 |
10 |
Pollen |
301 |
14,802 |
11 |
25 |
CBMC |
7,895 |
2,000 |
13 |
200 |
Muraro |
2,126 |
19,156 |
10 |
200 |
See Preparing Your Data to add custom datasets.